目录
OSS简介
阿里云对象存储OSS(Object Storage Service)是阿里云提供的海量、安全、低成本、高可靠的云存储服务。其数据设计持久性不低于99.9999999999%(12个9),服务可用性(或业务连续性)不低于99.995%。
OSS具有与平台无关的RESTful API接口,您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。用户可以使用阿里云提供的API、SDK接口或者OSS迁移工具轻松地将海量数据移入或移出阿里云OSS。数据存储到阿里云OSS以后,用户可以选择标准存储(Standard)作为移动应用、大型网站、图片分享或热点音视频的主要存储方式,也可以选择成本更低、存储期限更长的低频访问存储(Infrequent Access)、归档存储(Archive)作为不经常访问数据的存储方式。
详细介绍、试用与定价请移步:https://help.aliyun.com/product/31815.html
下载文件
组里有一个和厂商的合作项目,需要我们从对方OSS上读取一批数据,当前数据量较小可以通过client进行读取(参考《下载文件》章节),但是后续数据量可能增加,清洗逻辑也可能更复杂,最终选择使用Spark进行数据读取和处理。从阿里云OSS读取数据有两种方式,一种通过OSS SDK读取,另一种是通过JindoFS SDK读取。下面将通过具体代码展示两种数据读取方式的异同。
Spark+OSS SDK
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>com.aliyun.emr</groupId>
<artifactId>emr-core</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.10.2</version>
</dependency>
</dependencies>
需要添加emr-core和aliyun-sdk-oss依赖,否则在读取OSS数据时会提示无法找到chema为oss的路径:
Exception in thread "main" java.io.IOException: No FileSystem for scheme: oss
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2421)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2428)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:88)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2467)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2449)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:367)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:287)
直接上Demo代码:
package com.w3sun.oss
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: w3sun
* @date: 2020/7/8 20:45
* @description:
*
*/
object AliOSSApp {
def main(args: Array[String]): Unit = {
//填写OSS配置信息
val endpoint = "oss-cn-beijing.aliyuncs.com"
//填写真实id
val accessKeyId = "accessKeyId"
//填写真实secret
val accessKeySecret = "accessKeySecret"
//填写真实bucketName
val bucketName = "bucketName"
//填写真实objectName
val objectName = "objectName"
//初始化SparkConf
val sparkConf: SparkConf = new SparkConf()
.setAppName("AliOSSApplication")
.setMaster("local[*]")
//设置OSS与Spark集成参数
sparkConf.set("spark.hadoop.fs.oss.impl", "com.aliyun.fs.oss.nat.NativeOssFileSystem")
sparkConf.set("spark.hadoop.mapreduce.job.run-local", "true")
sparkConf.set("spark.hadoop.fs.oss.accessKeyId", accessKeyId)
sparkConf.set("spark.hadoop.fs.oss.accessKeySecret", accessKeySecret)
//初始化SparkContext
val sparkContext: SparkContext = new SparkContext(sparkConf)
//拼接OSS上文件的存储路径
val input: String = s"oss://${bucketName}.${endpoint}/${objectName}"
//从OSS中读取的数据其实也是一行一行的String字符串
val ossData: RDD[String] = sparkContext.textFile(input)
ossData.foreachPartition(it => {
it.foreach(println)
})
sparkContext.stop()
}
}
运行结果:
20/07/08 23:08:02 INFO NativeOssFileSystem: Opening 'oss://bucketName.oss-cn-beijing.aliyuncs.com/objectName' for reading this is a sentence for word count. this is a sentence for word count. this is a sentence for word count. this is a sentence for word count. 20/07/08 23:08:03 INFO BufferReader: Closing input stream for 'objectName'. 20/07/08 23:08:03 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1158 bytes result sent to driver 20/07/08 23:08:03 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 1462 ms on localhost (executor driver) (2/2)
- Demo对隐私数据进行了脱敏,参考使用时对示例代码中的accessKeyId、accessKeySecret、bucketName、objectName进行真实值替换即可。
- 本地调试运行Spark代码读写OSS数据时,需要配置SparkConf,设置spark.hadoop.mapreduce.job.run-local为true,阿里云上是通过E-MapReduce或者MaxCompute操作OSS,Spark在外网IDC机房中是否可以通过Cluster访问OSS数据由于时间原因未测试,通过测试的同学可以联系本人进行更新。
Spark+JindoFS SDK
除了通过Spark+aliyun-sdk-oss读取OSS数据外,阿里云还支持Spark+JindoFS SDK组合进行数据读取。什么是JindoFS呢?JindoFS是一种云原生的文件系统,结合OSS和本地存储,成为E-MapReduce产品的新一代存储系统,为上层计算提供了高效可靠的存储。
JindoFS 提供了块存储模式(Block)和缓存模式(Cache)的存储模式。
JindoFS 采用了本地存储和OSS的异构多备份机制,Storage Service提供了数据存储能力,首先使用OSS作为存储后端,保证数据的高可靠性,同时利用本地存储实现冗余备份,利用本地的备份可以加速数据读取;另外,JindoFS 的元数据通过本地服务Namespace Service管理,从而保证了元数据操作的性能(和HDFS元数据操作性能相似)。
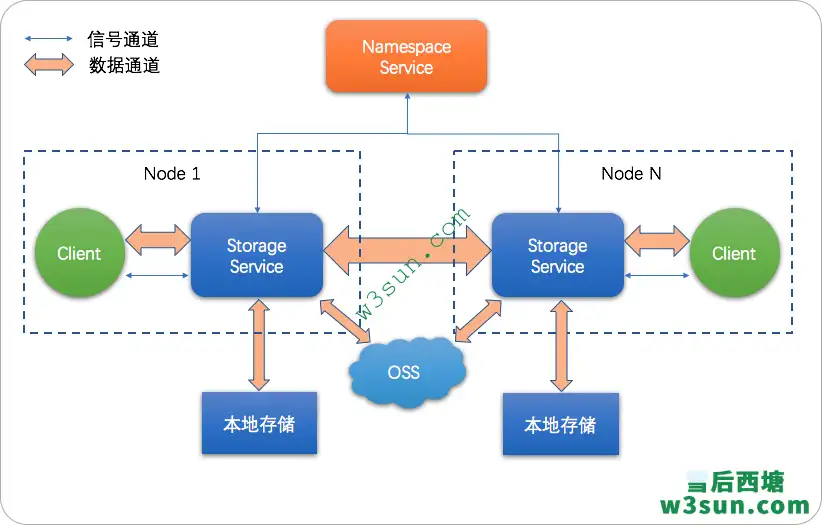
JindoFS SDK是一个简单易用面向Hadoop/Spark生态的OSS客户端,为阿里云OSS提供高度优化的Hadoop FileSystem实现。通过它用户可以
- 访问OSS(作为 OSS 客户端)
- 访问JindoFS Cache模式集群
- 访问JindoFS Block模式集群
即使使用JindoFS SDK(只支持Linux与Mac OS)仅仅作为OSS客户端,相对于Hadoop社区OSS客户端实现用户还可以获得更好的性能和阿里云E-MapReduce产品技术团队更专业的支持。目前支持的Hadoop版本包括Hadoop 2.7+和Hadoop 3.x,详情参见:《JindoFS SDK 使用》,其中给出了JindoFS SDK和Hadoop-OSS-SDK性能对比测试,感兴趣的读者可以参考官方文档。以下将给出Spark+JindoFS SDK读取OSS数据的具体代码,首先添加pom依赖:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>${jar.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
</dependencies>
JindoFS SDK依赖既可以通过pom方式引入,也可以单独新建一个lib文件夹引入 jindofs-sdk-x.x.x.jar ,本文采用后者。
通过JindoFS SDK请求数据时访问的URI与第一种方式略有不同,SparkConf参数也需要进行相应调整:
oss://{accessKeyId}:{accessKeySecret}@{bucketName}.{endpoint}/{objectName}
package com.w3sun.oss
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: w3sun
* @date: 2020/7/8 21:45
* @description:
*
*/
object AliOSSApp {
def main(args: Array[String]): Unit = {
val endpoint = "endpoint"
val accessKeyId = "accessKeyId"
val accessKeySecret = "accessKeySecret"
val bucketName = "bucketName"
val objectName = "objectName"
//初始化SparkConf
val sparkConf: SparkConf = new SparkConf()
.setAppName("AliOSSApplication")
.setMaster("local[*]")
//设置OSS与Spark集成参数
sparkConf.set("fs.AbstractFileSystem.oss.impl", "com.aliyun.emr.fs.oss.OSS")
sparkConf.set("fs.oss.impl", "com.aliyun.emr.fs.oss.JindoOssFileSystem")
//初始化SparkContext
val sparkContext: SparkContext = new SparkContext(sparkConf)
//拼接OSS上文件的存储路径, oss://<ak>:<secret>@<bucket>.<endpoint>/
val input: String = s"oss://${accessKeyId}:${accessKeySecret}@${bucketName}.${endpoint}/${objectName}"
//从OSS中读取的数据其实也是一行一行的String字符串
val ossData: RDD[String] = sparkContext.textFile(input)
val samples: Array[String] = ossData.take(2)
samples.toBuffer.foreach(println)
sparkContext.stop()
}
}
运行结果:
20/07/08 23:18:03 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1006 bytes result sent to driver 20/07/08 23:18:03 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 16592 ms on localhost (executor driver) (1/2) this is a sentence for word count. this is a sentence for word count. 20/07/08 23:18:03 INFO FsStats: cmd=download, src=oss://bucketName.endpoint/objectName, dst=null, size=3050859, parameter=byteReaded:2002283, time-in-ms=16144, version=2.7.1 20/07/08 23:18:03 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1006 bytes result sent to driver 20/07/08 23:18:03 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 16659 ms on localhost (executor driver) (2/2) 20/07/08 23:18:03 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 20/07/08 23:18:03 INFO DAGScheduler: ResultStage 0 (foreachPartition at AliOSSApp.scala:42) finished in 16.866 s 20/07/08 23:18:03 INFO DAGScheduler: Job 0 finished: foreachPartition at AliOSSApp.scala:42, took 17.087912 s
比较遗憾的是IDC中的服务器如果不具备外网访问权限是无法读取Aliyun OSS上存储的数据的,在三台联网机器上运行可以读取相应内容并完成计算:

可能遇到的问题
1.Mac OS
Referenced from: /private/var/folders/qh/676_k89s0bsg_cpj9g7042br0000gn/T/libjboot-ed376a31ece9bc6a_20200623_141838.dylib (which was built for Mac OS X 10.15)
Expected in: /usr/lib/libSystem.B.dylib
Referenced from: /private/var/folders/qh/676_k89s0bsg_cpj9g7042br0000gn/T/libjboot-ed376a31ece9bc6a_20200623_141838.dylib (which was built for Mac OS X 10.15)
Expected in: /usr/lib/libSystem.B.dylib
解决方法:系统升级到10.15+
2.Linux(CentOS)
解决方法:Settings->Build,Execution,Deployment->Compiler->Java Compiler->Project bytecode version设置成JDK版本
参考资料
转载请注明:雪后西塘 » Spark访问Aliyun OSS