目录
背景
模型文件重要性不言而喻,除了权限控制以外定期备份也是一个必要的安全措施。公司在迁移机房前与模型训练相关的集群有两个,分别是位于同一个物理机房下的Hadoop Cluster A和Hadoop Cluster B,其中Cluster A作为算法专用集群存储Paddle、TF和图模型的模型文件,Cluster B主要提供备份功能(含HDFS存储和DistCp执行所依赖的YARN)。容器中运行的调度程序每隔1个小时都会检查模型文件是否更新,如果有则通过DistCp Java API将各类有更新的模型文件备份一次。
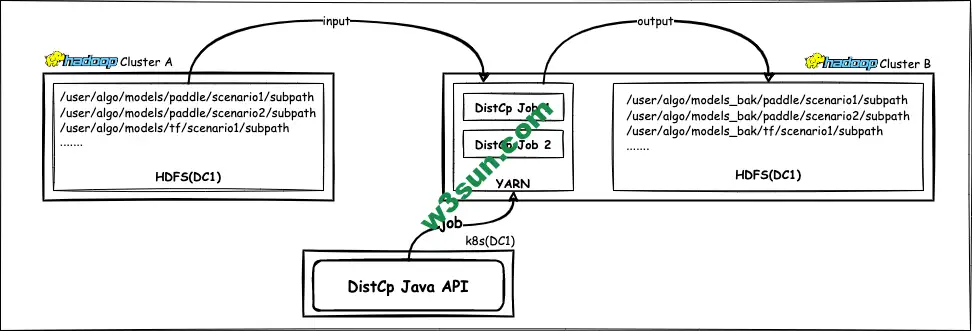
迁移完成后由于DC1的ClusterB计算资源不足后期才能扩容,短期内模型文件的备份涉及到了两个物理机房中的三个Hadoop Cluster:

中间由于人员变动负责模型备份功能的同学离职之前由于集群出现一些问题这个功能也暂停了,不幸的是最近公司出现了一次模型误删除,比较庆幸的是通过不断努力“被删除”模型文件完全恢复了,这个后续有时间补充一篇文章。因为要重启的模型备份功能涉及到一部分Hadoop的东西,领导让我协助那个同学一起看看。
恢复之前首先和同学确认了下,新的模型备份功能完全迁移到DC2,包括存储、计算和容器服务:
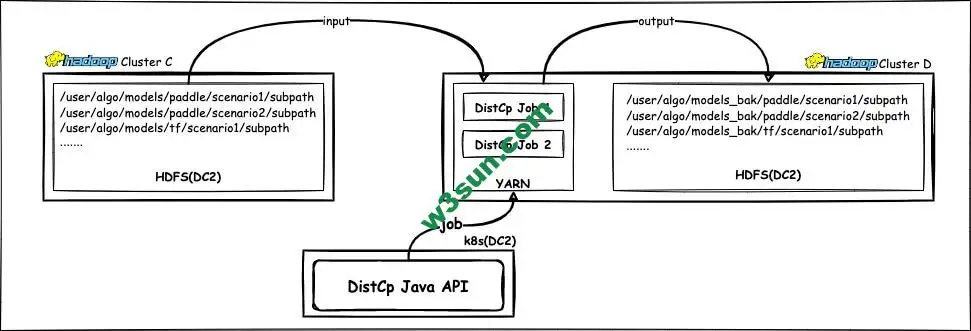
Java API提交DistCp任务
DistCp介绍
开始前简单介绍一下Hadoop DistCp工具,DistCp(分布式拷贝)是一个用于大规模集群内部和集群之间进行数据拷贝的工具。 它使用Map/Reduce实现文件分发,错误处理和恢复以及结果报告的生成。 它把文件和目录列表作为map任务输入,每个任务各自负责源列表中一部分文件的拷贝。 由于使用了Map/Reduce 框架其性能上相比 hdfs dfs -get/put 等通过本地文件系统中转的数据同步方案要高效快速很多。
既可以通过Azkaban这样的调度系统结合脚本语言执行DistCp,也可以通过Java API结合Spring生态进行平台化建设。详细介绍和使用方法可以参考:https://hadoop.apache.org/docs/stable/hadoop-distcp/DistCp.html
Java API提交拷贝任务
因为需要和Spring生态集成,模型在不同集群之间的拷贝任务通过Java API实现,接下来给出可直接用于生产环境的代码:
private int distcp(String srcHdfsPath, String destHdfsPath) {
try {
final Path srcPath = new Path(srcHdfsPath);
final Path destPath = new Path(destHdfsPath);
final DistCpOptions options = new DistCpOptions(srcPath, destPath);
//不需要同步
options.setSyncFolder(false);
options.setDeleteMissing(false);
//同副本复制需要校验filechecksums
options.setSkipCRC(false);
//不能忽略map错误
options.setIgnoreFailures(false);
//核心数据需要覆盖目标目录已经存在的文件
options.setOverwrite(true);
options.setBlocking(true);
options.setMaxMaps(100);
options.setMapBandwidth(10);
options.preserve(DistCpOptions.FileAttribute.USER);
options.preserve(DistCpOptions.FileAttribute.GROUP);
options.preserve(DistCpOptions.FileAttribute.TIMES);
options.preserve(DistCpOptions.FileAttribute.PERMISSION);
options.preserve(DistCpOptions.FileAttribute.REPLICATION);
//必须确保块大小相同,否则会导致filechecksum不一致
options.preserve(DistCpOptions.FileAttribute.BLOCKSIZE);
options.preserve(DistCpOptions.FileAttribute.CHECKSUMTYPE);
final String[] argv = {"-update", srcHdfsPath, destHdfsPath};
final Configuration configuration = getDefaultConf();
DistCp distCp = new DistCp(configuration, options);
return ToolRunner.run(configuration, distCp, argv);
} catch (Exception e) {
log.warn(e.getMessage(), e);
}
return -1;
}
DistCp异常问题排查
检查了几个分支并确认master分支为最新代码,编译打包到线上并成功触发备份操作,MR任务可以正常提交到YARN上但是程序无法运行
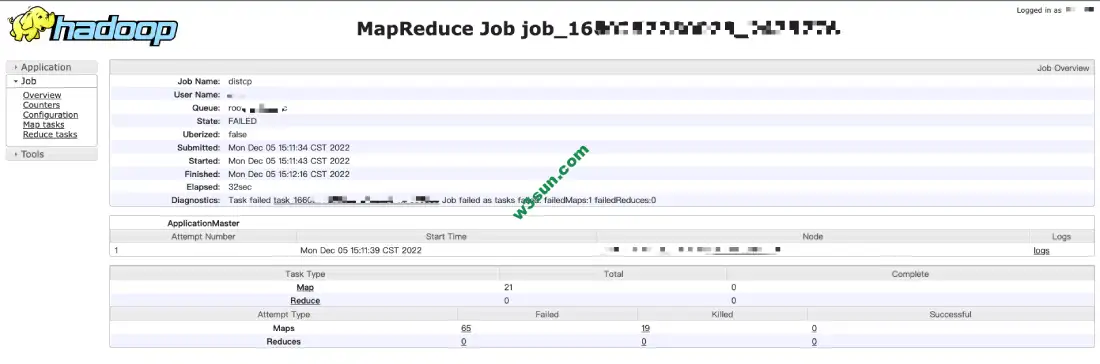
查看log发现一个不是很清晰的异常,这个异常:
2022-12-05 15:11:49,611 WARN [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Metrics system not started: org.apache.commons.configuration.ConfigurationException: Unable to load the configuration from the URL file:/run/cloudera-scm-agent/process/18124-yarn-NODEMANAGER/hadoop-metrics2.properties
2022-12-05 15:11:49,660 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens:
2022-12-05 15:11:49,660 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1660257230023_2475776, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@78ffe6dc)
2022-12-05 15:11:49,832 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now.
2022-12-05 15:11:50,043 INFO [main] org.apache.hadoop.mapred.YarnChild: mapreduce.cluster.local.dir for child: /path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776,/path/yarn/nm/usercache/root/appcache/application_1660257230023_2475776
2022-12-05 15:11:50,235 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2022-12-05 15:11:50,676 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2022-12-05 15:11:50,677 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-12-05 15:11:50,685 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2022-12-05 15:11:50,852 INFO [main] org.apache.hadoop.mapred.MapTask: Processing split: /user/user/.staging/_distcp828786942/fileList.seq:25504+2568
2022-12-05 15:11:50,857 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2022-12-05 15:11:50,857 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-12-05 15:11:52,277 WARN [main] org.apache.hadoop.security.UserGroupInformation: PriviledgedActionException as:root (auth:SIMPLE) cause:java.io.EOFException
2022-12-05 15:11:52,278 WARN [main] org.apache.hadoop.mapred.YarnChild: Exception running child : java.io.EOFException
at java.io.DataInputStream.readFully(DataInputStream.java:197)
at java.io.DataInputStream.readLong(DataInputStream.java:416)
at org.apache.hadoop.tools.CopyListingFileStatus.readFields(CopyListingFileStatus.java:366)
at org.apache.hadoop.io.serializer.WritableSerialization$WritableDeserializer.deserialize(WritableSerialization.java:71)
at org.apache.hadoop.io.serializer.WritableSerialization$WritableDeserializer.deserialize(WritableSerialization.java:42)
at org.apache.hadoop.io.SequenceFile$Reader.deserializeValue(SequenceFile.java:2332)
at org.apache.hadoop.io.SequenceFile$Reader.getCurrentValue(SequenceFile.java:2305)
at org.apache.hadoop.mapreduce.lib.input.SequenceFileRecordReader.nextKeyValue(SequenceFileRecordReader.java:78)
at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.nextKeyValue(MapTask.java:562)
at org.apache.hadoop.mapreduce.task.MapContextImpl.nextKeyValue(MapContextImpl.java:80)
at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.nextKeyValue(WrappedMapper.java:91)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:793)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
2022-12-05 15:11:52,284 INFO [main] org.apache.hadoop.mapred.Task: Runnning cleanup for the task
2022-12-05 15:11:52,576 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system shutdown complete.
这时候意识到pom.xml中的依赖可能出现了和集群环境不一致的情况,经过检查发现机房迁移之前Hadoop版本是Hadoop 2.6.0-cdh5.5.0而新机群的版本是Hadoop 2.6.0-cdh5.16.2,虽然主版本都是2.0但是通过查看代码发现后者基本相当于社区版2.8.0版本了,机房迁移之前的版本是兼容社区版本的2.6.0所以可以正常运行。
另外忘记记录现场classpath了,现在任务在线上正常运行也不好意思重新来一遍了毕竟不是自己小组的东西。感兴趣的同学可以对比下两个版本SequenceFileRecordReader和org.apache.hadoop.tools.CopyListingFileStatus.readFields的实现。
将pom.xml文件中的hadoop依赖进行升级之后再部署到线上,这个异常就消失了模型拷贝任务也可以正常执行。

这个也算水了一篇吧,本来打算好好写一篇的但是写到一半的时候阳了由于身体不舒服就没有写,中间电脑还重启了一次导致一些分析丢失了,如果后续有机会再补充下如果没有水了也就水了。