目录
Scala简介

Scala是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特性。Scala运行于Java平台(Java虚拟机),并兼容现有的Java程序。Scala的编译模型(独立编译,动态类加载)与Java和C#一样,所以Scala代码可以调用Java类馆(对于.NET实现则可调用.NET类库)。Scala包包括编译器和类库,以BSD许可证发布。Scala具有以下优点:
- 速度快:Scala是静态编译的,所以和JRuby,Groovy比起来速度会快很多;
- 风格优雅:框架与API是否优雅直接影响用户体验;
- Hadoop生态:Hadoop现在是大数据事实标准,Spark并不是要取代Hadoop,而是要完善Hadoop生态。JVM语言大部分可能会想到Java,但Java做出来的API太丑,或者想实现一个优雅的API较为困难。

[title]Scala编译器安装[/title]
安装JDK
Scala是运行在JVM平台上的,所以安装Scala之前要安装JDK,请自行参考其他资料安装Window、Linux或者MacOS所对应版本JDK。
Windows安装Scala编译器
访问Scala官网http://www.scala-lang.org/下载Scala编译器安装包,目前最新版本是2.12.x,但是目前大多数的框架都是用2.11.x编写开发的,Spark2.x使用的就是2.11.x,所以这里推荐2.11.x版本,下载scala-2.11.8.msi后点击下一步就可以了。msi版本安装以后自己注册环境变量不需要用户手动添加。
Linux安装Scala编译器
下载Scala地址http://downloads.typesafe.com/scala/2.11.8/scala-2.11.8.tgz然后解压Scala到指定目录
tar -zxvf scala-2.11.8.tgz -C /usr/ #配置环境变量,将scala加入到PATH中 vi /etc/profile export JAVA_HOME=/usr/java/jdk1.8.0_111 export SCALA_HOME=/usr/java/scala-2.11.8 export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin source /etc/profile
Scala开发工具安装
目前Scala的开发工具主要有两种:Eclipse和IDEA,这两个开发工具都有相应的Scala插件,如果使用Eclipse,直接到Scala官网下载即可http://scala-ide.org/download/sdk.html。
由于IDEA的Scala插件更优秀,大多数Scala程序员都选择IDEA,可以到http://www.jetbrains.com/idea/download/下载社区免费版,点击下一步安装即可,安装时如果有网络可以选择在线安装Scala插件。这里我们使用离线安装Scala插件:
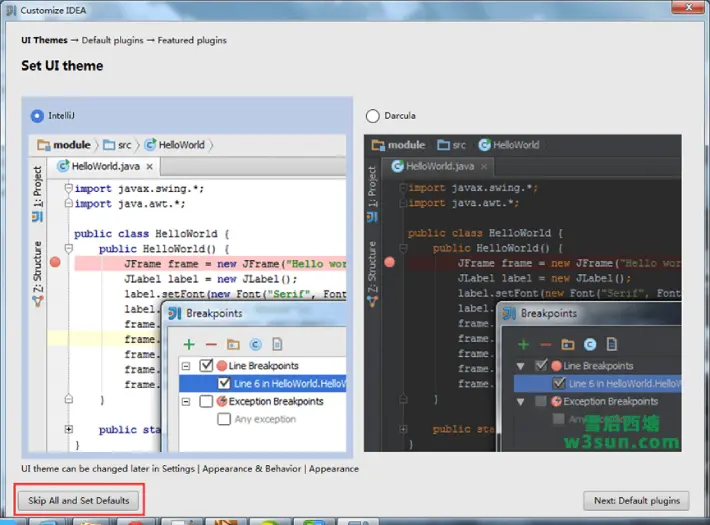
1.安装IDEA,点击下一步即可。由于离线安装插件所以点击Skip All and Set Default
2.下载IEDA的scala插件,地址http://plugins.jetbrains.com/?idea_ce

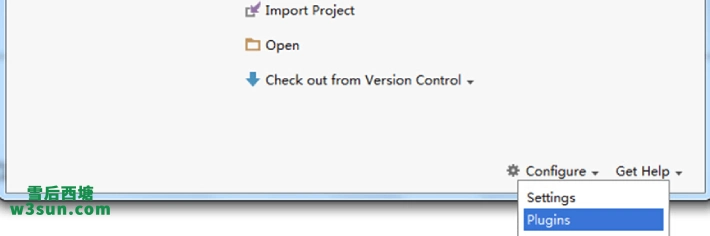
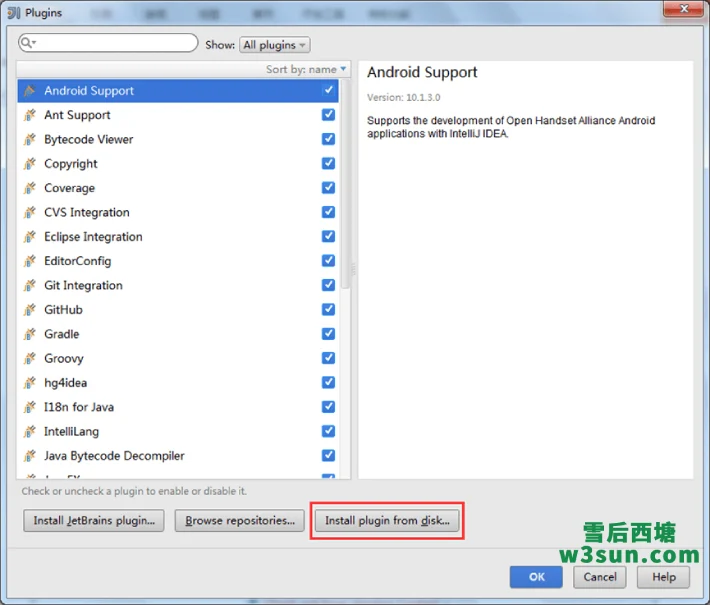
3.安装Scala插件:Configure -> Plugins -> Install plugin from disk -> 选择Scala插件 -> OK -> 重启IDEA
编译环境验证
安装完毕后需要进行验证以确保变成环境可用,本文将首先验证命令行模式后验证IDEA插件是否安装成功。
命令行环境验证
w3sun@w3sundeMacBook-Pro >~ > scala
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_111).
Type in expressions for evaluation. Or try :help.
scala> val arr=Array(1,2,3,4)
arr: Array[Int] = Array(1, 2, 3, 4)
scala> for(ele <- arr){
| println(ele*10)
| }
10
20
30
40
定义一个包含1,2,3,4共计4个元素的数组,在遍历数组的时候将每个元素乘以10并输出到控制台,从输出可以看到程序运行符合预期,命令行编译环境安装成功。
IDEA环境验证
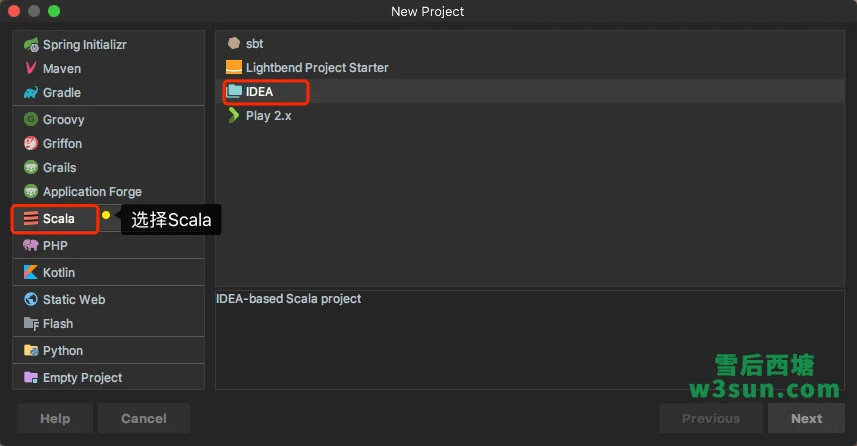
通过IDEA新建一个Scala工程:
object Demo {
def main(args: Array[String]): Unit = {
val arr: Array[String] = Array("hadoop","spark","hive")
arr.map("apache ".concat).foreach(println)
}
}
apache hadoop
apache spark
apache hive
定义一个String类型的数据,其中包含三个元素分别是”hadoop”,”spark”,”hive”。通过map算子在每个元素前拼接一个”apache “,打印结果符合预期说明IDEA环境配置已经生效。接下来让我们快乐地学习《Scala基础语法》吧。
转载请注明:雪后西塘 » Scala简介与环境配置