目录
重写Cube级别kylin.properties文件的默认配置
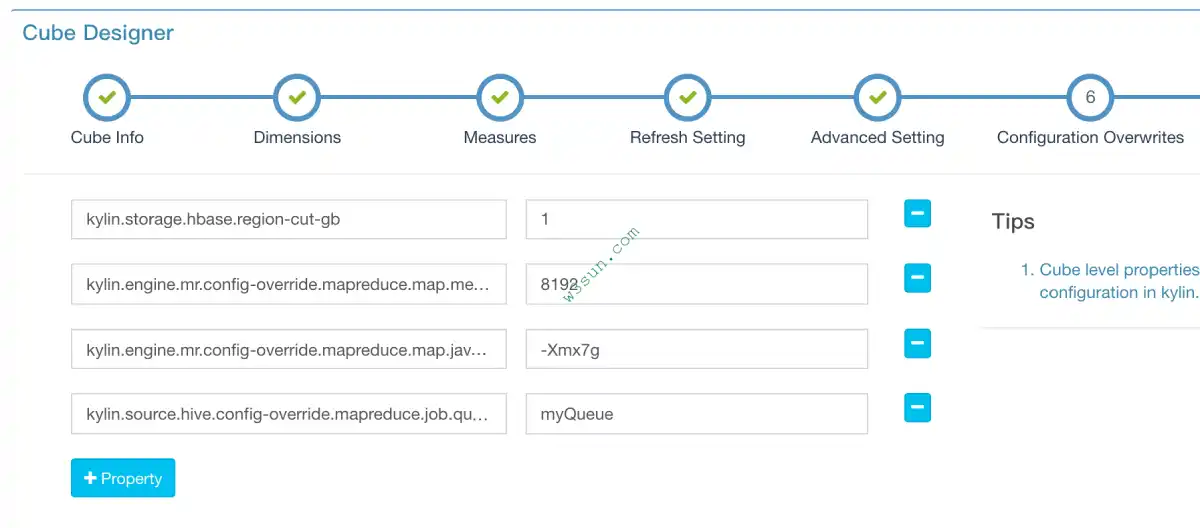
在conf/kylin.properties中有很多参数,这些参数控制/影响着Kylin的行为;大多数配置参数是全局的,其中一些参数和安全(security)或作业(job)相关,一些参数和Cube相关。这些和Cube相关的参数可以在Cube级别进行自定义,这使得Kylin配置起来更加灵活。在Cube向导“Configuration Overwrites”步骤中可以通过GUI来进行相关配置的更改,如下屏幕截图所示:
这里举两个例子:
- kylin.cube.algorithm: 定义了作业引擎(job engine)所选择的Cubing算法,默认值为“auto”,代表引擎(engine)将通过对数据进行采样来动态选择算法(“layer”或“inmem”),你如果对Kylin和其处理的数据/集群(data/cluster)比较了解则可以直接设置你的首选算法。
- kylin.storage.hbase.region-cut-gb: 定义了创建HBase表时region的大小,每个region默认大小为5(GB)。 对于一些小型或中型Cube来说,5(GB)可能太大了,可以为其设置一个较小的值以便生成更多的region从而获得更好的查询性能。
重写Cube级别Hadoop作业的默认配置
conf/kylin_job_conf.xml和conf/kylin_job_conf_inmem.xml 管理着Hadoop作业的默认配置。如果有需要对Cube自定义配置,可以用上述类似方式实现,但需要添加一个前缀“kylin.engine.mr.config-override”。 这些配置在提交作业时将被解析出来并应用到作业(job)中。以下是两个例子:
- 如果希望一个Cube作业可以从Yarn获取更多的内存资源,可以进行如下配置:
kylin.engine.mr.config-override.mapreduce.map.java.opts=-Xmx7g
kylin.engine.mr.config-override.mapreduce.map.memory.mb=8192
- 如果希望Cube作业可以进入Yarn中不同的资源队列,可以进行如下配置:
kylin.engine.mr.config-override.mapreduce.job.queuename=myQueue (“myQueue” 只是举例, 请更改为生产环境中实际队列名称)
重写Cube级别Hive作业的默认配置
转载请注明:雪后西塘 » Kylin 2.0.0高级设置