目录
开发经验总结
1.JStorm spout中nextTuple和ack/fail运行在不同的线程中, 从而鼓励用户在nextTuple里面执行block的操作。 Storm中nextTuple和ack/fail在同一个线程中,不允许nextTuple/ack/fail执行任何block的操作否则就会出现数据超时,但带来的问题是,在没有数据情况下整个spout仍然会不停地空跑极大地浪费了cpu。因此,JStorm更改了storm的spout设计,鼓励用户block操作(比如从队列中take消息)从而节省cpu。
2.业务开发时架构上推荐采用 “消息中间件 + jstorm + 外部存储/消息中间件” 架构,该架构非常方便JStorm程序进行重启(如升级程序),而且职责上也较为清晰,可以有效减少和外部系统的交互,JStorm将计算结果存储到外部存储后,用户无需访问JStorm服务进程即可进行查询。
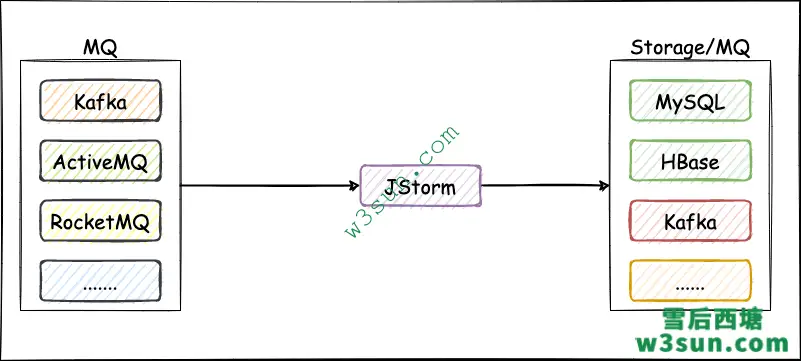
- 通常消息中间件推荐使用RocketMQ,Kafka,外部存储推荐使用HBase,Mysql,Redis,ES等;
- JStorm从消息中间件中读取数据,计算出结果后存储到外部存储上/消息中间件,写入消息中间件的数据后续可以Dump到HDFS,挂载成Hive表后非常方便查询;
- 实际应用中可能会涉及到数据修正,因此在设计整个项目时需要考虑重跑功能。此外数据和计算结果尽量携带时间戳,如果落盘到hadoop可以挂载成Hive的分区表,如果写入数据库则可以时间戳限制查询;
3.使用异步Kafka/MetaQ客户端(listener方式)时,当增加/重启meta时,均需要重启topology。
4.使用trasaction模式增加Kafka/MetaQ broker数量时, brokerId要按自然序递增即新增机器brokerId要比之前的都要大,这样reassign spout消费brokerId时就不会发生错位。
5.非事务环境中,尽量基于IBasicBolt接口开发满足业务功能的实现类;
6.计算并行度时,spout 按单task每秒500的QPS计算并发,全内存操作的task按每秒2000个QPS计算并发(如果涉及Cache,推荐采用Guava Cache),有向外部输出结果的task按外部系统承受能力进行计算并发。
7.对于MetaQ 和 Kafka拉取的频率不要太小,低于100ms时容易造成MetaQ/Kafka 空转次数偏多。此外,一次获取数据Block大小推荐是2M或1M,如果单条数据太大会导致内存较大的GC压力,单条数据太小效率比较低。
8.推荐一个worker运行2个task,生产环境下根据服务器性能进行相应增减,目前集群中业务逻辑最重的JStorm任务单worker平均运行80个task。此外尽量在应用中提供业务指标或者任务异常告警,实时计算任务出现异常需要尽可能快的定位和解决问题。
9.JStorm 0.9.5.1 开始底层通信框架netty同时支持同步模式和异步模式:
- 异步模式下,应用性能更好但容易造成spout出现fail,该模式更适合无acker应用,通过参数storm.messaging.netty.sync.mode: false控制;
- 同步模式下,JStorm框架接收端接收一条消才能发送一条消息,该模式适合有acker应用,通过参数storm.messaging.netty.sync.mode: true控制;
10.使用zookeeper时可以通过使用apache curator代替,但不要使用过高版本的curator;
运维经验总结
1. 启动supervisor或nimbus时最好是以后台方式启动以避免终端退出时向JStorm发送信号进而导致进程莫名其妙地退出;
[staff@workstation ~]# nohup jstorm supervisor >/dev/null 2>&1 &
2.推荐使用具备sudo权限的用户启动集群,尤其是不要用root用户启动web ui。在安装目录下建议使用jstorm-current链接,比如当前使用版本是jstorm 0.9.4则创建一个软链接指向jstorm-0.9.4,后续升级时只需要将jstorm-current链接指向新JStorm版本即可。
[staff@workstation ~]# ln -s /opt/jstorm-0.9.4 jstorm-current
3.将JStorm本地目录和日志配置到一个公共目录下,比如/home/admin/jstorm_data和/home/admin/logs,请勿配置到$JSTORM_HOME/data和$JSTORM_HOME/logs,当版本升级时如果替换整个目录则容易丢失所有本地数据和日志。
4.JStorm支持环境变量JSTORM_CONF_DIR,当设置了该变量时框架会从该目录里读取storm.yaml文件,建议设置该变量。JSTORM_CONF_DIR变量指定的目录存放有storm.yaml配置文件,升级时简单的替换目录即可。
5.建议不超过1个月强制重启一下supervisor,因为supervisor是一个daemon进程会不停地创建子进程,当使用时间过长时文件打开的句柄会非常多,这将导致worker的启动时间会变慢,建议每隔一周强制重启一次supervisor。
6.JStorm web ui推荐使用apache tomcat 7.x, 默认端口为8080, 如果需要将80 端口重定向到8080时可以通过root用户执行如下命令:
[staff@workstation ~]# iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8080
7.JStorm框架建议采用CMS垃圾回收器, JStorm默认已经采用上述设置, 使用Storm的朋友可以采取类似的设置:
worker.childopts: "-Xms1g -Xmx1g -Xmn378m -XX:SurvivorRatio=2 -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=65"
8.对于一些重要的应用可以对大集群进行拆分, 修改配置文件的 storm.zookeeper.root和 nimbus.host以保证高优任务的稳定性。
9.对于使用Zookeeper较频繁的应用需要将JStorm集群依赖的Zookeeper和应用的Zookeeper进行物理隔离。nimbus节点上建议不运行supervisor,并且建议把nimbus调度到Zookeeper所在机器上以增强集群稳定性,此外Zookeeper的maxClientCnxns建议设置为500。
10.推荐slot数为 “CPU 核数 – 1”,假设服务器CPU为24核, 则slot设置为为23。配置cronjob以定时检查nimbus和supervisor,一旦发现进程死去可以快速重启相应进程。此外,需要考虑Linux对外连接端口数限制,当TCP client对外发起连接数达到28000左右时,JStorm框架就开始大量抛异常,用户可以增加连接数设置:
[staff@workstation ~]# echo "10000 65535" > /proc/sys/net/ipv4/ip_local_port_range
JStorm框架性能优化
1. 按照性能来说trident < transaction < 使用ack机制普通接口 < 关掉ack机制的普通接口,因此需要根据实际业务形态决定应该选用什么方式来完成任务。“使用ack机制普通接口”时可以尝试关掉ack机制,如果性能有大幅提升则预示着瓶颈不在spout,有可能是acker的并发设置偏少或者业务逻辑处理较慢(需要检查外部依赖是否正常)导致。
2.数据处理延迟较高时可以尝试简单增加task并发度,并查看是否能够增加数据处理能力,可以通过worker日志检查是否有异常抛出。
3.当使用fieldGrouping方式Hash时有可能造成有的task任务重有的task任务轻,最后导致整个数据流变慢, 尽量让task之间压力均匀。
4.使用MetaQ和Kafka时一个分区只能被一个spout线程消费,简单增加并发无法解决问题且确认外部依赖无异常情况下可以尝试增加MetaQ和Kafka的分区数。
参考文档
https://github.com/alibaba/jstorm
https://groups.google.com/g/jstorm-user
转载请注明:雪后西塘 » JStorm运维开发与性能优化