目录
Alibaba JStorm简介
JStorm是一个由Alibaba开源的企业级流式计算引擎,通过Java重写了Apache Storm模型所以重命名为JStorm。相对Apache Storm而言JStorm做了许多改进,其性能是Apache Storm的4倍并且可以自由地在成行模式或mini-batch 模式之间切换。JStorm 提供企业级的Exactly-Once编程框架,并已经大面积在阿里巴巴关键的核心应用上使用,如菜鸟、阿里妈妈、支付宝的计费或统计系统上,并且它的性能远超传统的Acker模式(至少一次模式)。
JStorm 不仅提供一个流式计算引擎,还提供实时计算的完整解决方案, 涉及到许多组件如jstorm-on-yarn,jstorm-on-docker,SQL Engine,Exactly-Once Framework等。

JStorm是Apache Storm的超集包含Storm的所有API,应用可以很轻松地从Apache Storm迁移到JStorm上,并且基于Apache Storm 0.9.5版本的应用可以不进行需修改的前提下无缝迁移到JStorm 2.1.1 版本,该版本也是当前公司使用的主要版本。
JStorm是一个类似Hadoop MapReduce的系统,用户按照指定接口编写具体业务实现类然后将这个任务提交给JStorm流式计算框架。JStorm会将这个任务按7 * 24小时运行起来。一旦中间一个Worker发生意外故障,调度器立即分配一个新Worker来替换这个失效的Worker。从应用的角度看,JStorm应用是一种遵守某种编程规范的分布式应用。从系统角度看,JStorm是一套类似MapReduce的调度系统。 从数据的角度看,JStorm是一套基于流水线的消息处理机制。实时计算现在是大数据领域中最火爆的一个方向,因为人们对数据的实时性要求越来越高,传统的Hadoop MapReduce逐渐满足不了数据实时性的需求。
JStorm组件和Hadoop组件对比:
| 框架名称 | JStorm | Hadoop |
|---|---|---|
| 角色 | Nimbus | JobTracker |
| Supervisor | TaskTracker | |
| Worker | Child | |
| 应用名称 | Topology | Job |
| 编程接口 | Spout/Bolt | Mapper/Reducer |
Storm和JStorm出现以前市面上出现很多实时计算引擎,但自Storm和JStorm出现后基本上可以说一统江湖:究其优点主要有以下几个方面:
- 灵活性:接口简单容易上手,只要遵守Topology、Spout和Bolt编程规范即可开发出一个扩展性极好的应用,底层RPC、Worker之间冗余,数据分流之类的动作完全不用考虑;
- 扩展性:直接配置一下并发数即可提升一级处理单元速度,即框架数据处理性能可线性扩展;
- 健壮性:当Worker失效或机器出现故障时,自动分配新的Worker替换失效Worker;
- 准确性:可以采用Ack机制,保证数据不丢失。 如果对精度有更多一步要求可采用事务机制以保证数据准确;
- 实时性: JStorm 设计偏向单行记录,数据时延较同类产品更低;
Alibaba JStorm应用场景
JStorm处理数据的方式是基于消息的流水线处理,因此特别适合无状态计算,也就是计算单元依赖的数据全部在接受的消息中可以找到并且最好一个数据流不依赖另外一个数据流。因此,常常用于:
- 日志分析,从日志中分析出特定的数据并将分析的结果存入外部存储,如关系/非关系型数据库、消息队列等。目前主流日志分析技术就使用JStorm或Storm;
- 管道系统,将数据从一个系统传输到另外一个系统, 比如将数据库、消息队列数据同步到HDFS;
- 消息转换,将接收到的消息进行清洗或者按照某种格式进行转换,最后存储到另外一个系统如消息中间件;
- 统计分析,从日志或消息中提炼出某些字段,然后做count、sum、窗口内的avg计算,最后将统计值存入外部存,中间处理过程可能更复杂。
- 实时推荐,将推荐算法运行在JStorm中,达到秒级的推荐效果;
Alibaba JStorm基本概念
JStorm有点类似于Apache Hadoop的MR(Map-Reduce),但是区别在于Hadoop的MapReduce框架在提交的MR Job执行完毕后进程就退出,相应的Container会消亡。而一个JStorm任务(JStorm中称为Topology)是7*24小时永远运行的,除非用户主动kill掉当前的Topology。
JStorm组件
接下来是一张比较经典的Storm结构图(跟JStorm一样):
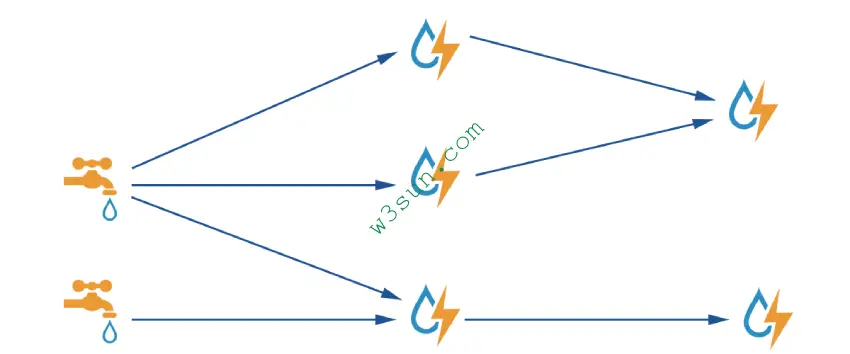
图中的水龙头就被称作spout,图中的闪电被称作bolt。在JStorm的Topology中有两种组件:Spout和Bolt。
Spout
Spout代表输入的数据源,这个数据源可以是任意的,比如说Kafka,DB,HBase甚至是HDFS等,JStorm从这个数据源中不断地读取数据,然后发送到下游的Bolt中进行处理。
Bolt
Bolt代表处理逻辑,Bolt收到消息之后对消息做处理(即执行用户的业务逻辑),处理完以后既可以将处理后的消息继续发送到下游的Bolt形成一个处理流水线(Pipeline,不过更精确的应该是个有向图),也可以直接结束。通常一个流水线的最后一个Bolt会做一些数据的存储工作,比如将实时计算出来的数据写入DB、HBase等以供前台业务进行查询和展现。
组件的接口
JStorm框架对spout组件定义了一个接口:nextTuple,顾名思义就是获取下一条消息。执行时可以理解成JStorm框架会不停地调这个接口以从数据源拉取数据并发送数据到下游Bolt。同时,Bolt组件定义了一个接口:execute,这个接口就是用户用来处理业务逻辑的地方。每一个Topology,既可以有多个Spout,代表同时从多个数据源接收消息,也可以多个Bolt来执行不同的业务逻辑。
调度和执行
接下来就是Topology的调度和执行原理,JStorm会为一个Topology调度一个或多个Worker,每个Worker即为一个真正的操作系统执行进程,分布到一个集群的一台或者多台机器上并行执行。每个Worker中又可以有多个task,分别代表一个执行线程。每个task就是上面提到的组件(Component)的实现,要么是Spout要么是Bolt。用户在提交一个Topology的时候,会指定以下的一些执行参数:
总Worker数
即总的进程数。举例来说,用户提交一个Topology,如果指定Worker数为3那么最后可能会有3个进程执行。之所以是可能是因为根据配置JStorm有可能会添加内部的组件,如acker或者topology_master(这两个组件都是特殊的Bolt),这样会导致最终执行的进程数大于用户指定的进程数。JStorm流式计算框架下,如果用户设置的Worker数小于10个,那么topology_master 只是作为一个task存在并不独占Worker。如果用户设置的Worker数量大于等于10个,那么topology_master将作为一个task将独占一个Worker。
Component并行度
上文提到每个Topology都可以包含多个Spout和Bolt,而每个Spout和Bolt都可以单独指定一个并行度(parallelism),代表同时有多少个线程(task)来执行这个Spout或Bolt。JStorm中每一个执行线程都有一个task id,它从1开始递增,每一个Component中的task id是连续的。
假设存在一个JStorm Topology包含一个Spout和一个Bolt,Spout的并行度为5,Bolt并行度为10。那么最终会有15个线程来执行:5个Spout执行线程,10个Bolt执行线程。这时Spout的task id可能是1~5,Bolt的task id可能是6~15,之所以是可能是因为JStorm在调度的时候并不保证task id一定是从Spout开始然后才是Bolt的,但是同一个Component中的task id一定是连续的。
Component之间的关系
用户需要指定一个特定Spout发出的数据应该由哪些Bolt来处理,或者说一个中间的Bolt,它发出的数据应该被下游哪些Bolt处理。还是以上面的Topology为例,它会分布在3个进程中。JStorm使用了一种均匀的调度算法,因此在执行的时候你会看到每个进程分别都各有5个线程在执行。当然,由于Spout是5个线程不能均匀地分配到3个进程中,会出现一个进程只有1个spout线程的情况。同样地,也会出现一个进程中有4个Bolt线程的情况。
在一个Topology的运行过程中,如果一个进程(Worker)挂掉了,JStorm检测到之后会不断尝试重启这个进程,这就是7*24小时不间断执行的概念。
消息的通信
上面提到Spout的消息会发送给特定的Bolt,Bolt也可以将消息再发送给其他的Bolt,那这之间是如何通信的呢?首先,Spout发送消息的时候,JStorm会计算出消息要发送的目标task id列表,然后检查目标task id是否在本进程中,如果在本进程中那么就可以直接走进程内部通信(如直接将这个消息放入本进程中目标task的执行队列中),如果是跨进程,那么JStorm会使用netty来将消息发送到目标task中。
实时计算结果输出
JStorm是7*24小时运行的,外部系统如果需要查询某个特定时间点数据处理的结果,并不会直接请求JStorm(当然,DRPC可以支持这种需求,但是性能并不是太好)。一般来说,在JStorm的Spout或Bolt中都会有一个定时向外部存储写计算结果的逻辑,这样数据可以按照业务需求被实时或者近实时地存储起来然后直接查询外部存储中的计算结果即可。
参考资料
http://jstorm.io/QuickStart_cn/BasicConception.html
https://github.com/alibaba/jstorm
https://groups.google.com/g/jstorm-user
转载请注明:雪后西塘 » JStorm流式计算框架