目录
Grouping方式介绍
- fieldsGrouping
-
- 类似SQL中的Group By保证相同Key的数据会发送到下游相同的task,其原理是对某个或几个字段做Hash然后用Hash结果求模得出目标TaskId;
-
- globalGrouping
-
- Target Component的第一个Task;
-
- shuffleGrouping
-
- 通过轮询方式将数据平均分配Tuple到下一级Component上;
-
- localOrShuffleGrouping
-
- 当前Worker进程优先,如果本Worker内有目标Component的Task则随机从本Worker内部的目标Component Task中进行选择否则就和普通的shuffleGrouping一样;
-
- localFirstGrouping
-
- 本Worker优先级最高,如果本Worker内有目标component的task则随机从本Worker内部的目标component的Task中进行选择;
- 本节点优先级其次, 当本Worker不能满足条件时如果本Supervisor下其他Worker有目标Component的Task则随机从中选择一个task进行发送;
- 当上叙2种情况都不能满足时则从其他Supervisor节点的目标Task中随机选择一个Task进行发送;
-
- noneGrouping
-
- 随机发送Tuple到目标Component上但无法保证平均;
-
- allGrouping
-
- 发送给Target Component所有Task;
-
- directGrouping
-
- 发送指定目标Task;
-
- customGrouping
-
- 实现自定义接口CustomStreamGrouping选择出目标task;
-
IBasicBolt 接口介绍
事实上很多使用JStorm/Storm的人无法分清BasicBolt和IRichBolt之间的区别,建议尽可能的使用IBasicBolt。IRichBolt继承自IBolt,IBolt会使用OutputCollector来发送元组。
public interface IBolt extends Serializable {
...
void prepare(Map stormConf, TopologyContext context, OutputCollector collector);
...
}
OutputCollector有两个用于发送元组的函数:
//后续component会向acker发送ack响应。
List<Integer> emit(String streamId, Tuple anchor, List<Object> tuple)
//后续component不会向acker发送ack响应。
List<Integer> emit(String streamId, List<Object> tuple) {
IBasicBolt使用BasicOutputCollector来发送元组:
public interface IBasicBolt extends IComponent {
...
void execute(Tuple input, BasicOutputCollector collector);
...
}
BasicOutputCollector只有第二个emit函数,但是这个函数包裹了OutputCollector第一个emit函数来完成工作:
//out是一个OutputCollector实例.
List<Integer> emit(String streamId, List<Object> tuple) {
return out.emit(streamId, inputTuple, tuple);
}
IBasicBolt中emit(String streamId, List<Object> tuple)是用于处理元组的可靠方法。但是,IRichBolt中它不是一个可靠的方法。在使用IRichBolt时如果要可靠地处理元组,应该显式地调用emit(String streamId, Tuple anchor, List<Object> tuple) 。
JStorm Acker详解
Acker概述
JStorm的acker机制能够保证消息至少被处理一次(at-least-once),也就是说能够保证不丢消息,这里就详细解析一下acker的实现原理。假设我们有一个简单的Topology,结构为Spout -> Bolt。 Spout emit了一条消息发送至Bolt,Bolt作为最后一个处理者没有再向下游emit消息。
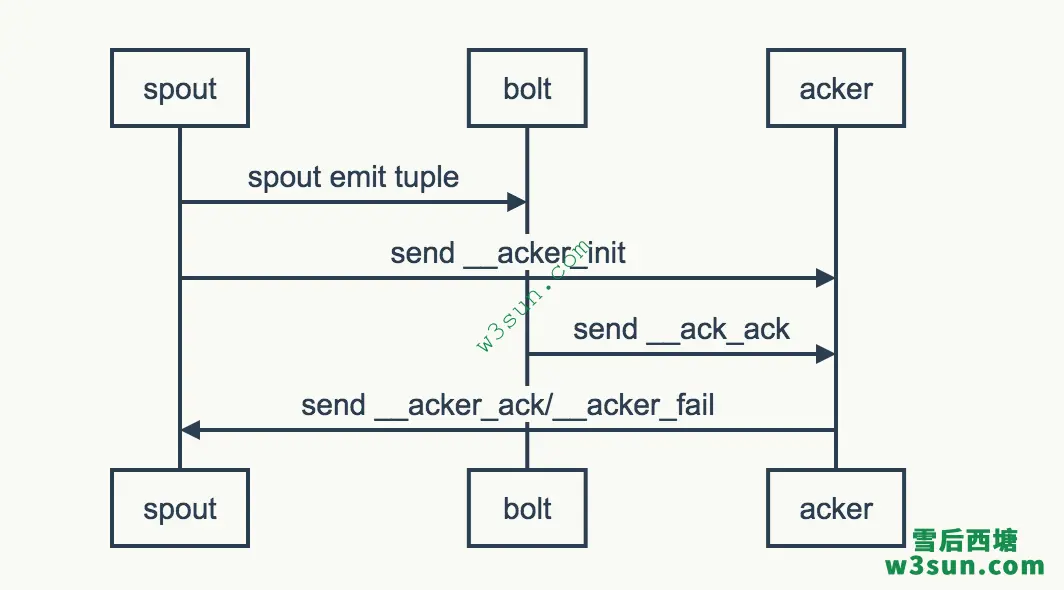
从上图可以看到所有的ack消息都会发送到acker,acker会根据算法计算出从特定Spout发射出来的tuple tree是否被完全处理。如果成功处理则发送__acker_ack消息给Spout否则发送__acker_fail消息给Spout,然后Spout中可以做相应的逻辑如重发消息等。在JStorm中acker是一种Bolt,因此它的数据处理和消息发送跟正常的Bolt是一样的。只不过acker是JStorm框架创建的Bolt,用户不能自行创建。如果用户在代码中使用:
Config.setNumAckers(conf, 1);
就会自动创建并行度为1的acker Bolt,如果为0则就不会创建acker Bolt了。
如何判断消息是否被成功处理
acker的算法非常巧妙它利用了数学上的异或操作来实现对整个tuple tree的判断。在一个Topology中一条消息形成的tuple tree中,所有的消息都会有一个MessageId,其内部其实就是一个map:Map<Long, Long> _anchorsToIds,其中存储的是anchor和anchor value。而anchor其实就是root_id,其在Spout中生成并且一路透传到所有的Bolt中,属于同一个tuple tree中的消息都会有相同的root_id可以唯一标识Spout发出来的这条消息(以及从下游Bolt根据这个tuple衍生发出的消息)。下面是一个tuple的ack流程:
- Spout发送消息时先生成root_id;
- 对每一个目标Bolt Task生成<root_id, random()>,即为这个root_id对应一个随机数值,然后随着消息本身发送到下游bolt中。假设有2个Bolt生成的随机数对分别为:<root_id, r1>, <root_id, r2>;
- Spout向acker发送ack_init消息,其MessageId = <root_id, r1 ^ r2>(即所有task产生的随机数列表的异或值);
- Bolt收到Spout或上游Bolt发送过来的tuple之后首先会向acker发送ack消息,MessageId即为收到的值。同时,如果Bolt下游还有Bolt则跟步骤2类似,会对每一个Bolt生成随机数对,root_id相同,但是值变为当前值 ^ 新生成的随机数,以此类推;
- acker收到消息后会对root_id下所有的值做异或操作,如果算出来的值为0表示整个tuple tree被成功处理,否则就会一直等待直到超时,如果超时则tuple tree处理失败;
- acker通知Spout消息处理成功或失败;
以一个稍微复杂一点的Topology为例描述一下整个过程, 假设Topology结构为: Spout -> Bolt1/Bolt2->Bolt3 即Spout同时向Bolt1和Bolt2发送消息,它们处理完后都向Bolt3发送消息,Bolt3没有后续处理节点。
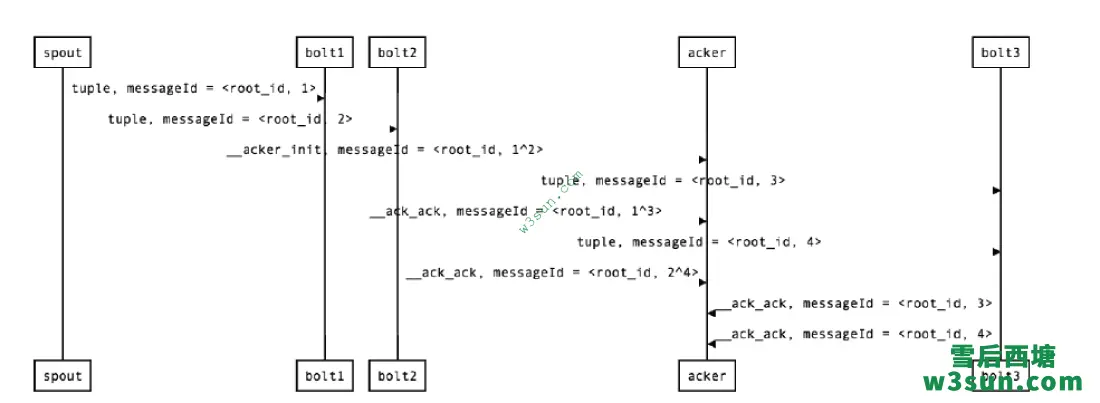
- Spout发射一条消息生成root_id,由于这个值不变就用root_id来标识。 Spout ->Bolt1的MessageId = <root_id, 1>, Spout -> Bolt2的MessageId = <root_id, 2>, spout -> acker的MessageId = <root_id, 1^2>;
- Bolt1收到消息后生成如下消息: Bolt1 -> Bolt3的MessageId = <root_id, 3>,Bolt1->acker的MessageId = <root_id, 1^3>;
- Bolt2收到消息后生成如下消息: Bolt2 -> Bolt3的MessageId = <root_id, 4>,Bolt2->acker的MessageId = <root_id, 2^4>;
- Bolt3收到消息后生成如下消息: Bolt3 -> acker的MessageId = <root_id, 3>,Bolt3->acker的MessageId = <root_id, 4>;
- acker中总共收到以下消息: <root_id, 1^2> <root_id, 1^3> <root_id, 2^4> <root_id, 3> <root_id, 4> 所有值进行异或之后即为1^2^1^3^2^4^3^4 = 0;
如何使用acker
1.设置acker的并发度要>0;
2.Spout发送消息时使用的接口为List emit(List tuple, Object messageId),其中messageId由用户指定生成,用户消息处理成功或者失败后用于对public void ack(Object messageId) 和public void fail(Object messageId) 接口的回调;
3.如果Spout同时从IAckValueSpout和IFailValueSpout派生,则要求实现void fail(Object messageId, List values)和void ack(Object messageId, List values),这两接口除了会返回messageId还会返回每一条消息;
4.Bolt一般从如果从IRichBolt派生,发送消息到下游时要注意以下两种不同类型的接口:
public List<Integer> emit(Tuple anchor, List<Object> tuple); //anchor 代表当前bolt接收到的消息, tuple代表发送到下游的消息 public List<Integer> emit(List<Object> tuple); //如果对即将发送的消息不打算acker的话,可以直接用第二种接口;如果需要对即将发送的下游的消息要进行acker的话,emit的时候需要携带anchor
5.如果Bolt接收到的消息是需要被acker的话得在execute里头别忘了执行_collector.ack(tuple)操作,例子如下:
@Override
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0)));
_collector.ack(tuple);
}
6.对于从IRichBolt派生的的Bolt来说是不是很麻烦,即要求采样合适的emit接口还要求主动执行acker操作,如果当前Bolt是从IBasicBolt派生的话内部都会帮你执行这些操作,用户只管调用emit(List tuple)发送消息即可,例子如下:
public class PairCount implements IBasicBolt {
private static final long serialVersionUID = 7346295981904929419L;
public static final Logger LOG = LoggerFactory.getLogger(PairCount.class);
private AtomicLong sum = new AtomicLong(0);
private TpsCounter tpsCounter;
public void prepare(Map conf, TopologyContext context) {
tpsCounter = new TpsCounter(context.getThisComponentId() + ":" + context.getThisTaskId());
LOG.info("Successfully do parepare " + context.getThisComponentId());
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
tpsCounter.count();
Long tupleId = tuple.getLong(0);
Pair pair = (Pair) tuple.getValue(1);
sum.addAndGet(pair.getValue());
// 如果需要ack,只需要这么做:
collector.emit(new Values(tupleId, pair));
}
public void cleanup() {
tpsCounter.cleanup();
LOG.info("Total receive value :" + sum);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("ID", "PAIR"));
}
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}
使用API提交Topology
使用JavaAPI提交程序的核心接口是:
public static void submitTopology(String name, Map stormConf, StormTopology topology, SubmitOptions opts, List<File> jarFiles)
- name表示TopologyName;
- stormConf是conf对象,里面需要包括defaults.yaml中的参数,zkRoot,zkServer的IP;
- topology是要提交的topology对象;
- jarFiles是依赖的jar文件的文件对象;
下面是一个例子:
public static void submit(StromTopology topology, File jarFile, String zkRoot, List<String> zkIps) {
Yaml yaml = new Yaml();
Map<String, Object> allConfig = new HashMap<String, Object>();
allConfig.putAll(parse(yaml, "/defaults.yaml"));
allConfig.put(Config.STORM_ZOOKEEPER_ROOT, zkRoot);
allConfig.put(Config.STORM_ZOOKEEPER_SERVERS, zkIps);
List<File> topologyJars = new ArrayList<File>();
topologyJars.add(jarFile);
StormSubmitter.submitTopology(name, allConfig, topology, null, topologyJars);
}
public static Map<String, Object> parse(Yaml yaml, String file) {
@SuppressWarnings("unchecked")
Map<String, Object> conf = (Map<String, Object>) yaml.load(new InputStreamReader(getClass().getResourceAsStream(file)));
if (conf == null) {
conf = new HashMap<String, Object>();
}
return conf;
}
JStorm限流控制/反压
背景与原理
限流控制又称反压 或者背压(backpressure),这个概念现在在大数据领域非常火爆尤其是最近Heron/Spark都实现了这个功能。其实在jstorm 0.9.0 时底层netty的同步模式就可做到限流控制, 即当接收端能处理多少tuple发送端才能发送多少tuple, 但随着大面积使用发现netty的同步模式会存在死锁问题, 故这种方式并没有被大量使用。
2015年6月twitter发布了heron的一篇论文, 描叙了当下游处理速度更不上上游发送速度时他们采取了一种暴力手段立即停止Spout的发送。 这种方式 JStorm拿过来进行压测发现存在大量问题,当下游出现阻塞时上游停止发送下游消除阻塞后上游又开闸放水,过了一会儿下游又阻塞上游又限流如此反复整个数据流一直处在一个颠簸状态。真正合适的状态是:上游降速到一个特定的值后下游的处理速度刚刚跟上上游的速度。
触发反压的条件
JStorm的限流机制是当下游Bolt发生阻塞时,如果阻塞task的比例超过某个比例时(现在默认设置为0.1)随即启动反压。 即假设一个Component有100个并发,当这个Component超过10个task 发生阻塞时,才会触发启动反压限流。JStorm连续4次采样周期中采样队列情况,当队列占用超过80%(可以设置)时即可认为该task处在阻塞状态。
判断触发限流的Spout
根据阻塞Component,沿着DAG向上推算直到推算到源头Spout, 并将topology的一个状态位设置为 “限流状态”。
限流与解除限流
当task出现阻塞时会将其执行线程的执行时间传给Topology Master, 当触发Topology Master阻塞后会把这个执行时间传给Spout。于是Spout每发送一个tuple就会等待这个执行时间,Storm 社区的人想通过动态调整max_pending达到这种效果,其实这种做法根本无效。
当Spout降速后,发送过阻塞命令的task检查队列水位连续4次低于0.05时会发送解除反应命令到Topology Master,Topology Master发送提速命令给所有的Spout,当Spout的等待时间降为0时,Spout会不断发送“解除限速”命令给Topology Master, 而Topology Master确定所有降速的spout都发了解除限速命令时, 将Topology状态设置为正常标志真正解除限速。
JStorm限流配置
## 反压总开关 topology.backpressure.enable: true ## 高水位 -- 当队列使用量超过这个值时,认为阻塞 topology.backpressure.water.mark.high: 0.8 ## 低水位 -- 当队列使用量低于这个量时, 认为可以解除阻塞 topology.backpressure.water.mark.low: 0.05 ## 阻塞比例 -- 当阻塞task数/这个component并发 的比例高于这值时,触发反压 topology.backpressure.coordinator.trigger.ratio: 0.1 ## 反压采样周期, 单位ms topology.backpressure.check.interval: 1000 ## 采样次数和采样比例, 即在连续4次采样中, 超过(不包含)(4 *0.75)次阻塞才能认为真正阻塞, 超过(不包含)(4 * 0.75)次解除阻塞才能认为是真正解除阻塞 topology.backpressure.trigger.sample.rate: 0.75 topology.backpressure.trigger.sample.number: 4
此外可以通过动态配置调整:
jstorm update_topology topology-name -conf confpath
参考资料
https://github.com/alibaba/jstorm
https://groups.google.com/g/jstorm-user
https://storm.apache.org/index.html
转载请注明:雪后西塘 » JStorm编程进阶