目录
JStorm程序本地调试
JStorm提供了两种运行模式:本地模式和分布式模式。本地模式针对开发调试JStorm Topologies非常有用。接下来将介绍在本机不安装JStorm环境的情况下开发、调试JStorm程序。
模拟JStorm本地集群
单机模式需要用到LocalCluster,LocalCluster可以用来模拟JStorm本地集群环境,用户可以在LocalCluster对象上调用submitTopology方法来提交拓扑。submitTopology(String topologyName, Map conf, StormTopology topology)接受一个拓扑名称、拓扑相关配置以及一个拓扑对象。就像StormSubmitter一样,用户还可以调用killTopology来结束一个拓扑,对应的方法还有active、deactive、rebalance等。由于JStorm是个不会停止的程序,所以最后还需要用户显式地停掉集群。
import backtype.storm.LocalCluster;
LocalCluster cluster = new LocalCluster();
//建议加上这行,使得每个bolt/spout的并发度都为1
conf.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, 1);
//提交拓扑
cluster.submitTopology("SequenceTest", conf, builder.createTopology());
//等待1分钟, 1分钟后会停止拓扑和集群, 视调试情况可增大该数值
Thread.sleep(60000);
//结束拓扑
cluster.killTopology("SequenceTest");
cluster.shutdown();
调整JStorm Maven依赖
以jstorm 2.1.1版本为例,需要注意的地方是,在Maven pom.xml依赖中要注释掉JStorm依赖中的<scope>provided</scope>,而提交的时候必须记得将这行改回来,否则会报多个defaults.yaml的错误。
<dependency> <groupId>com.alibaba.jstorm</groupId> <artifactId>jstorm-core</artifactId> <version>2.1.1</version> <!-- keep jstorm out of the jar-with-dependencies --> <!-- <scope>provided</scope> --> </dependency>
通常最直接有效的办法是通过Maven Profile进行dev、test和prod环境的设置,通过不同的profile控制依赖的scope范围。
备注:
1.如果依赖的是 0.9.x 版本的JStorm会有三个依赖包,需要将这三个依赖的provided都注释掉。
2.本地调试主要是用于测试应用逻辑的正确性,因此有一些限制比如classloader在本地模式下是不起作用的。此外还需要注意一下log4j的依赖,如果应用的依赖中自带了log4j.properties,则有可能导致将JStorm默认的log4j配置被覆盖掉从而导致调试时控制台没有任何输出。
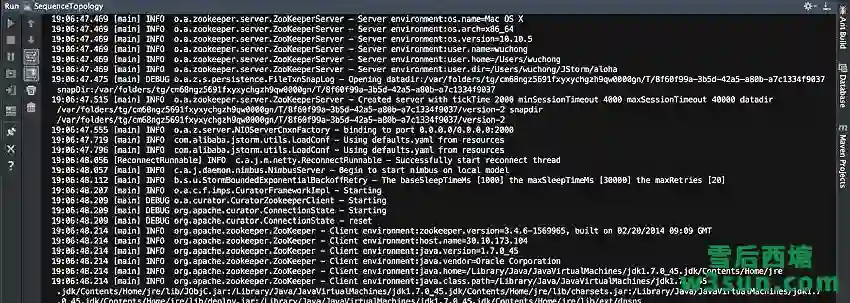
为了更好的代码组织,建议将本地运行和集群运行写成两个方法,根据参数/配置来调用不同的运行方式,更多可以参照[SequenceTopology示例]。
JStorm数据流分流与合并
数据流经常需要分流与合并操作,如下图所示:

请参考示例代码:https://github.com/alibaba/jstorm/tree/master/example/sequence-split-merge
数据流分流
分流有2钟情况,第一种是相同的tuple发往下一级不同的bolt, 第二种是分别发送不同的tuple到不同的下级bolt。
发送相同tuple
其实和普通1v1 发送一模一样,就是有2个或多个bolt接收同一个spout或bolt的数据,举例来说:
SpoutDeclarer spout = builder.setSpout(SequenceTopologyDef.SEQUENCE_SPOUT_NAME, new SequenceSpout(), spoutParal);
builder.setBolt(SequenceTopologyDef.TRADE_BOLT_NAME, new PairCount(), 1)
.shuffleGrouping(SequenceTopologyDef.SEQUENCE_SPOUT_NAME);
builder.setBolt(SequenceTopologyDef.CUSTOMER_BOLT_NAME, new PairCount(), 1)
.shuffleGrouping(SequenceTopologyDef.SEQUENCE_SPOUT_NAME);
发送不同的tuple
当发送不同的tuple到不同的下级bolt时,就需要引入Stream概念。发送方发送a消息到接收方A时使用Stream A,发送b消息到接收方B时使用stream B。在Topology提交时:
builder.setBolt(SequenceTopologyDef.SPLIT_BOLT_NAME, new SplitRecord(), 2)
.shuffleGrouping(SequenceTopologyDef.SEQUENCE_SPOUT_NAME);
builder.setBolt(SequenceTopologyDef.TRADE_BOLT_NAME, new PairCount(), 1)
.shuffleGrouping(
SequenceTopologyDef.SPLIT_BOLT_NAME, // --- 发送方名字
SequenceTopologyDef.TRADE_STREAM_ID // --- 接收发送方该stream 的tuple
);
builder.setBolt(SequenceTopologyDef.CUSTOMER_BOLT_NAME, new PairCount(), 1)
.shuffleGrouping(
SequenceTopologyDef.SPLIT_BOLT_NAME, // --- 发送方名字
SequenceTopologyDef.CUSTOMER_STREAM_ID // --- 接收发送方该stream 的tuple
);
在发送消息时, 需要注明消息属于那个流:
public void execute(Tuple tuple, BasicOutputCollector collector) {
tpsCounter.count();
Long tupleId = tuple.getLong(0);
Object obj = tuple.getValue(1);
if (obj instanceof TradeCustomer) {
TradeCustomer tradeCustomer = (TradeCustomer)obj;
Pair trade = tradeCustomer.getTrade();
Pair customer = tradeCustomer.getCustomer();
collector.emit(SequenceTopologyDef.TRADE_STREAM_ID,new Values(tupleId, trade));
//SequenceTopologyDef.TRADE_STREAM_ID就是流名称
collector.emit(SequenceTopologyDef.CUSTOMER_STREAM_ID,new Values(tupleId, customer));
// SequenceTopologyDef.CUSTOMER_STREAM_ID 就是流名称
}else if (obj != null){
LOG.info("Unknow type " + obj.getClass().getName());
}else {
LOG.info("Nullpointer " );
}
}
定义输出流格式:
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declareStream(SequenceTopologyDef.TRADE_STREAM_ID, new Fields("ID", "TRADE"));
declarer.declareStream(SequenceTopologyDef.CUSTOMER_STREAM_ID, new Fields("ID", "CUSTOMER"));
}
接受消息时,需要判断数据流:
if (input.getSourceStreamId().equals(SequenceTopologyDef.TRADE_STREAM_ID)) {
customer = pair;
customerTuple = input;
tradeTuple = tradeMap.get(tupleId);
if (tradeTuple == null) {
customerMap.put(tupleId, input);
return;
}
trade = (Pair) tradeTuple.getValue(1);
}
数据流合并
在下面例子中MergeRecord同时接收SequenceTopologyDef.TRADE_BOLT_NAME 和SequenceTopologyDef.CUSTOMER_BOLT_NAME 的数据,创建Topology:
builder.setBolt(SequenceTopologyDef.TRADE_BOLT_NAME, new PairCount(), 1)
.shuffleGrouping(SequenceTopologyDef.SPLIT_BOLT_NAME, SequenceTopologyDef.TRADE_STREAM_ID);
builder.setBolt(SequenceTopologyDef.CUSTOMER_BOLT_NAME, new PairCount(), 1)
.shuffleGrouping(SequenceTopologyDef.SPLIT_BOLT_NAME, SequenceTopologyDef.CUSTOMER_STREAM_ID);
builder.setBolt(SequenceTopologyDef.MERGE_BOLT_NAME, new MergeRecord(), 1)
.shuffleGrouping(SequenceTopologyDef.TRADE_BOLT_NAME)
.shuffleGrouping(SequenceTopologyDef.CUSTOMER_BOLT_NAME);
发送的bolt和普通一样无需特殊处理,接收方需要区分一下来源的Component即可识别出数据来源:
if (input.getSourceComponent().equals(SequenceTopologyDef.CUSTOMER_BOLT_NAME)) {
customer = pair;
customerTuple = input;
tradeTuple = tradeMap.get(tupleId);
if (tradeTuple == null) {
customerMap.put(tupleId, input);
return;
}
trade = (Pair) tradeTuple.getValue(1);
} else if (input.getSourceComponent().equals(SequenceTopologyDef.TRADE_BOLT_NAME)) {
trade = pair;
tradeTuple = input;
customerTuple = customerMap.get(tupleId);
if (customerTuple == null) {
tradeMap.put(tupleId, input);
return;
}
customer = (Pair) customerTuple.getValue(1);
}
JStorm事务机制
原有的Storm设计中Trident支持了只处理一次语义,Acker支持至少处理一次场景。但是Trident和Acker在这两种消息保证机制中都面临着同样的性能问题,如果用户需要exactly-once 保证, 性能会急剧下降。同时由于Trident和Acker机制的API完全不同,用户很难用一套代码去支持两个场景。针对这两个问题,急需一套新的框架来支持者两个消息保证机制。
事务基本原理
设计参考了Flink只处理一次的方案,即Barrier和Stream Align(流对齐)方案设计,如何做batch的划分和如何保证每个节点只会处理当前批次的消息,具体可以参考Flink的官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.0/internals/stream_checkpointing.html 对于Barrier和流对齐本文不详细展开,主要介绍JStorm的实现和相关接口的使用。
- 状态维护:JStorm把Topology任务的节点分为了四类节点:数据源Spout,状态无关节点non-stateful Bolt,状态节点Stateful Bolt,结束节点End bolt。数据源节点和状态节点只维护自己节点的状态提交顺序,在处理完每个batch后会马上处理下一个batch的消息。Topology Master负责每个batch的全局状态维护,需要确认是否所有节点都完成了当前batch的处理。如果完成topology master开始做全局snapshot状态的持久化存储。
- 如何回滚:
Barrier和Stream Align让每个节点在做checkpoint时都能够保证batch的顺序性和一致性,而Topology Master维护了全局状态。如果执行失败Topology Master会通知所有状态节点回滚到最后一次全局成功的checkpoint,然后数据源开始从最后一次全局成功的位置开始重新拉取消息。JStorm里回滚以数据源的种类为最小单位,比如说我们现在有两个Spout Component,TT Spout和MetaQ Spout。如果MetaQ Spout下游节点挂了,只会回滚MetaQ Spout这个流的数据。
事务接口介绍
Spout:ITransactionSpoutExecutor
Bolt:ITransactionBoltExecutor,ITransactionStatefulBoltExecutor
应用的消息处理接口和JStorm的基础API一致,如果用户从原有的JStorm任务迁移过来则消息的处理逻辑不用改变,只需要在Spout和状态Bolt节点实现以下状态处理相关的接口即可。
/** * Init state from user checkpoint * @param userState user checkpoint state */ public void initState(Object userState); /** * Called when current batch is finished * @return user state to be committed */ public Object finishBatch(); /** * Commit a batch * @param The user state data * @return snapshot state which is used to retrieve the persistent user state */ public Object commit(BatchGroupId id, Object state); /** * Rollback from last success checkpoint state * @param user state for rollback */ public void rollBack(Object userState); /** * Called when the whole topology finishes committing */ public void ackCommit(BatchGroupId id);
- initState和rollback:任务起来和回滚时用于让当前节点回到最后一次成功batch的checkpoint;
- finishBatch:通知用户当前batch接收完毕,返回值为当前batch对应的业务checkpoint;
- commit:在用户返回对应的checkpoint后会在一个异步线程里调用commit接口,对这个checkpoint进行提交操作以不阻塞task execute处理线程。如果checkpoint不大,可以直接在这个接口中返回checkpoint,JStorm最终会在Topology Master里统一做持久化。如果checkpoint比较大用户可以在这个接口中把对应的checkpoint缓存一份到相应外部存储里然后返回对应的key。在回滚时JStorm会把该key值返回给用户,用于找回对应的checkpoint;
- ackCommit:当topology任务在所有节点成功后该接口会被回调,如果之前有checkpoint的缓存用户在这个接口里可以去完成一些清理工作,比如batch-10完成了那可以删除batch-9和之前的所有checkpoint缓存;
参考示例:sequence-split-merge模块中TransactionTestTopology.java类。
架构优势与相关配置
相对于Trident和Acker机制,这套架构的最大优势在于:
- 每个节点只关心自己节点提交的状态,不用等待所有节点都成功后再开始下一个batch的提交和计算。
- 不需要再依赖acker节点,这样可以减少额外系统计算和带宽消耗。原有的acker模型下,每条用户消息都会产生一条对应的系统消息到acker同时有额外的计算消耗,并且acker消息会消耗大量的网络带宽。
相关配置通过以下选项控制:
# true: 只处理一次; false: 至少处理一次 transaction.exactly.once.mode: true
JStorm Trident概述
Trident是Storm 0.8.0版本引入的新特性,为基于Storm元语进行实时计算的用户提供了一类更高级的抽象元语,能够同时满足高吞吐量(每秒百万级的消息)与低处理延时。Trident提供了Partition-local,Repartitioning,Aggregation,Group,Merges and Joins这五类基本元语。同时,Trident延续了TransactionalTopology的exactly-once语义,能够满足用户一些事务性的需求但前提条件是对性能要有所牺牲。
举一个官方文档中的例子来简单介绍一下Trident的功能,这个例子中要完成两个功能:word count统计和通过执行查询得到一组单词的总数。下面代码为模拟输入的Spout代码:
FixedBatchSpout spout = new FixedBatchSpout(
new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some cand
new Values("four score and seven years ago"), new Values("
new Values("to be or not to be the person")
);
spout.setCycle(true); //true表示会循环的产生以上values
//如果我们要用Storm的基本元语来实现这个功能应该怎么做呢?创建一个TopologyBuilder
TridentTopology topology = new TridentTopology();
builder.setSpout("sentences",spout,5); //设置spout,component id设为sentences
builder.setBolt("split", new SplitSentence(), 8) //设置分句的bolt, 上游component为sentences
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 12) //设置统计word count的bolt,上游component为split,grouping策略是按word做hash
.fieldsGrouping("split",new Fields("word"));
DRPCClientclient = newDRPCClient("drpc.server.location",port); //再创建一个DRPC client, 但外部查询调用
/*
…//定义DRPC的代码
*/
其中SplitSentence与WordCount是两个Bolt类,而对于Trident来说,如何完成这个功能呢?一种实现是只通过Trident进行计算过程的描述,再单独创建一个DRPC client供查询调用:
TridentTopologytopology = newTridentTopology();
TridentStatewordCounts = topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(6);
// 再创建一个DRPC client, 但外部查询调用
DRPCClientclient = newDRPCClient("drpc.server.location", port);
//定义DRPC的代码
//另一种实现是直接通过Trident的Topology创建一个DRPCStream
topology.newDRPCStream("words")
.each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
上面的例子中,Split、Count和Sum是简单的Function而不再是Bolt。可以看出,通过Trident这层更高级的抽象层用户再也看不到Bolt,Ack,Emit,BatchBolt这样的概念,用户也不用纠结于execute和finishBatch里到底该写些什么。只需要根据业务需求的数据处理逻辑,对Stream进行简单的groupBy, aggregate等操作,而这些数据操作的基本概念显然是很容易理解的。当然以上只是Trident从API层面带来的最直观的优势,Trident更强大的地方在下文中会逐一介绍。
Trident基本概念
对于Trident来说用户所要关心的对象只有Stream,Trident的所有API也都是针对Stream。所以基本元语也不再是Storm的Spout, Bolt, Acker等,而是五类新的元语:
Partition-local operations
不需要网络传输,在local就能完成的操作,包括以下API:
- Function:用户自定义的Tuple操作函数;
- Filters:对Tuple进行过滤,如果isKeep返回false则过滤掉该Tuple;
- partitionAggregate:对同一个batch的数据进行local combiner操作;
- project: 只保留Stream中指定的Field;
- stateQuery和partitionPersist:partitionPersist会被计算的中间状态(state)写到持久化存储中,stateQuery可以从持久化查询中获得当前的state信息;
Repartition operations
决定Tuple如何分发到下一个处理环节的操作,包括以下API:
- shuffle: 采用random round robin算法将Tuple均匀的分发到所以目标分区;
- broatcase: 以广播的形式发分Tuple,所有的分区都会收到;
- partitionBy: 以某一个特定的Field进行Hash求余,分到某一个partition,该Field值相同的Tuple将会分到同一个partition,会被顺序执行;
- global: 所有Tuple将被发到指定的相同的分区;
- batchGlobal: 同一批的Tuple将被发到相同的分区,不同的批次发到不同的分区;
- partition: 用户自定义的分区策略
Aggregation operations
不同partition处理结果的汇聚操作,包括以下API:
- aggregation:只针对同一批的数据进行汇聚操作;
- persistentAggregation:针对所以批次的数据进行汇聚操作,并将计算的中间状态(state)保存在持久化存储中;
groupBy operations
对Stream中的Tuple进行重新分组,后续的操作将针对每一个分组独立进行,类似于sql里的groupBy。
Merges and Joins operations
将多个Stream融合为一个Stream,包括以下API:
- merge: 多个流进行简单的合并;
- join: 多个流按照某一个key进行union操作,join只能针对同一个batch的数据;
Trident一致性
Trident对进行读写资源的操作做了非常好的抽象工作,将这些有状态的操作全部融入到TridentTopology的内部,用户可以将Trident运行过程中间状态(State)写到Hbase,Mysql等关系型与非关系型DB产品中,这些操作对于Trident的API来说是没有任何区别的。
Trident通过以一种幂等的形式对State进行管理,即使在发生重试或操作处理节点挂掉的情况也能保证每一个Tuple会被处理一次(exactly-once semantics)。Trident定义了三个基本的语义就可以实现exactly once的功能:
- 所有的Tuples是以小批量的形式进行处理,而不是Storm基本功能中的单条数据处理;
- 每一批数据系统处理的过程中会生成一个严格递增的事务id(txid),如果这批数据因为处理超时或者没有正确处理完则这批数据将会被重发,重发后txid保持不变;
- 不同批次数据的计算是乱序执行,但中间状态(State)的提交是按照txid的顺序进行提交的。上一批数据的计算结果没有被正确提交则下一批数据的结果是不会被提交的;
当然,要做到exactly-once还需要源头Spout的配合。根据对不同容错级别的定义,Trident将spout分为三类:non-transactionalspout,transactional spout,opaque transactional spout。
Non-TransactionalSpout
顾名思义,Spout对每一批数据的容错处理不做任何保证,使用这类Spout无法做到exactly-once。如果一批数据处理失败进行不重发的话那么只能做到数据至多被处理一次。如果一批数据处理失败重发的话那么只能做到数据至少被处理一次,但是有可能出现同一条数据被处理多次。
TransactionalSpout
事务性的Spout,使用这类Spout用户可以很轻易做到exactly-once,但是这类Spout对消息队列要三个基本要求:
- Trident会给每批数据分配一个txid,给定一个txid得到的批次是相同,消息队列重发过来的数据必须与第一次来的数据有相同的txid;
- 不同批的数据之间不能有重叠部分;
- 每一个Tuple必须置于一个批次中不能漏数据;
使用Transactional Spout时用户维护中间状态的代码会变的非常简单,并且可以做到只处理一次,非常适用于counter场景。举一个WordCount的例子,数据库中当时状态:
man=> [count=3, txid=1] dog=> [count=4, txid=3] apple=> [count=10, txid=2] 现在来了一批数据,txid=3 [“man”] [“man”] [“dog”]
对于”man”来说最后一次来的txid=1,所以txid=3的数据是需要处理的。而对于”dog”来说最后一次来的txid=3,所以txid=3的数据已经处理过,由此可见这批是重发过来的不做处理。最后得到的结果是:
man=> [count=5, txid=3] dog=> [count=4, txid=3] apple=> [count=10, txid=2]
如果你所使用消息队列无法保证在系统可以根据指定的txid取得同一批的数据时,用户就没法满足Transactional Spout第一个基本要求,Transactional Spout就无能为力了。
Opaque TransactionalSpout
相比Transactional Spout而言Opaque Transactional Spout对消息队列的要求要宽松一些:
- 每一个Tuple都会在一个批次的数据中,如果在Tuple在某一批处理失败,可以将这个Tuple重发到后续的批次中;
- 不同批数据不能有重叠;
- 不可以漏数据;
Transactional Spout是透明的,用户只需要记录中间结果和最后一次成功处理的txid就能完成exactly-once的语义。而对于Opaque Transactional Spout来说对消息队列的要求宽松一些,但是对于用户的操作来说却无法做到透明。用户需要记录一些历史结果,配合Trident完成exactly-once的语义。再拿word count举例,假设一个word的当时状态如下:
{
value = 23, //当时统计的值
prevValue =1, // 在txid这批来之前的值
txid =2 // 最后一次处理过的批txid
}
假设现在来了一批数据这一批中这个word的统计值是20,txid=3,因为最新txid 是3大于最后一次处理过的txid,所以这次是新来的数据,最终结果值为原来的value加上这批新来的值。prevValue设为原来的value,最后一次处理过的txid设为3,最终的结果为:
{
value = 43
prevValue =23,
txid =3
}
但如果现在来的这批数据中txid=2,我们又将进行怎样的逻辑处理呢?因为最后一次处理过的txid也等于2,说明在处理txid=2的这批数据时整个Stream没有被完整的处理完,所以这批数据是重发的。那么就意味着要重新处理,所以新的value应该为prevValue+20,最终的结果为:
{
value = 21,
prevValue =1,
txid =2
}
这时有个疑问,在第一次计算txid=2的这批数据时得到的结果是23,而新的这批数据计算结果却为21,少了的那两条数据是丢了吗?这两条数据并没有丢失,每一个Tuple都会在一个批次的数据中,如果在Tuple在某一批处理失败,可以将这个tuple重发到后续的批次中。这两条数据将在后续的批次中重发,如果在还是像处理Transactional Spout那样,txid=2的这批数据直接不处理,就会导致多计算。通过上述对三类spout的比较,可以得出如下结论:
- Non-transactional Spout无法做到exactly-once;
- Transactional Spout可以做到exactly-once,且对于用户来说使用上的透明的。用户不需要关注值的中间状态,但对数据源头的要求是比较苛刻的;
- Opaque transactional Spout也可以做到exactly-once且功能是最强的,但对于用户的使用上来说需要精心的设计中间状态(State)的存储,对数据源头的要求相对要低一些;
参考资料
https://github.com/alibaba/jstorm
https://groups.google.com/g/jstorm-user
https://storm.apache.org/index.html
转载请注明:雪后西塘 » JStorm编程指南